RR_FINAL_#9
Here it is the final of the final of the final for Considering Religious Robots, and while we are at it let’s consider what a robot priest/overlord/demon might watch for Saturday morning cartoons.
Picking up where I left off, I had a list of audio files to be cut into segments that when stitched together might resemble what you might hear during a viewing session of “Saturday Morning Cartoons”. The audio sources I ended up using are as follows:
- 80s 90s Vintage Toy Commercials! Nostalgic TV ads with RAD Action Figures Retro Advert Compilation
- 2001 A Space Odyssey (1968)
- Ferris Bueller’s Day Off (1986)
- Hackers (1995)
- Saturday Morning Commercials from 1980-1989
- The Last Temptation Of Christ (1988)
- The Matrix
- The Rocky Horror Picture Show (1975)
- The Cook the Thief His Wife and Her Lover
I edited these into a single track with commercials interspersed in the audio. Sudden changes in sound result from would be channel changes, some form boredom others from a commercial starting. The end result was a track that was 1:53:44:.908 in length. Great. Perfect. Next step.

So now its time to upload the audio file to the Google Colab machine learning environment. Ready 3, 2, 1 GO! NOW wait 12 hours….
12 hours later…

WHAT!?!?!?!?!?!?!?! Timed out!!! 12hours of waiting for nothing!! OK lets do some more research.

Well cool wish I had done that research before, although there was no way for me to know how long a 2 hour audio file would take to process. So now I know, and just as GI Joe say “Knowing is half the battle!”
So let’s re-edit the audio, this time lets make it 29:00.074, lets hope this works!

It worked!!! 8:29.18 hours later a video was born. Now I just needed to find a place to host this copywrite-infringement-waiting-happen of a video. It’s ok though cause this is for education purposes.
I did Two version of the video one using a model weight generated from the previously mentioned data set and birds the other used the same data set and landscape. I wanted to have a stark contrast between the dataset which was very surreal and other-worldly and the natural environment in which we live.
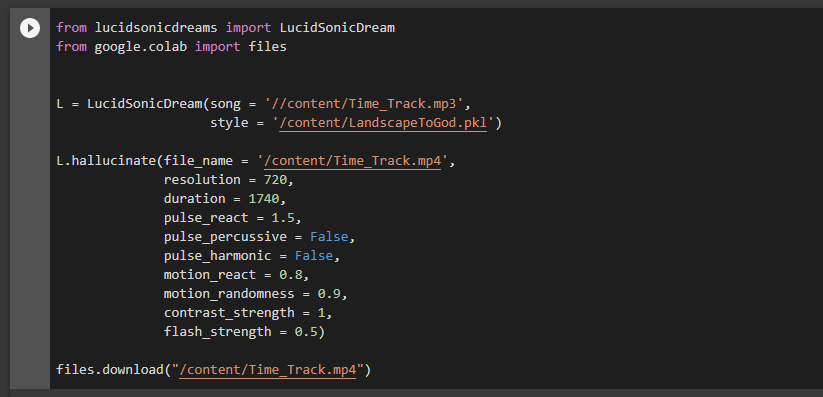
I adjusted the parameters inside of Google Colab for each attempt to see if there is a noticeable difference between the output of each, you be the judge.
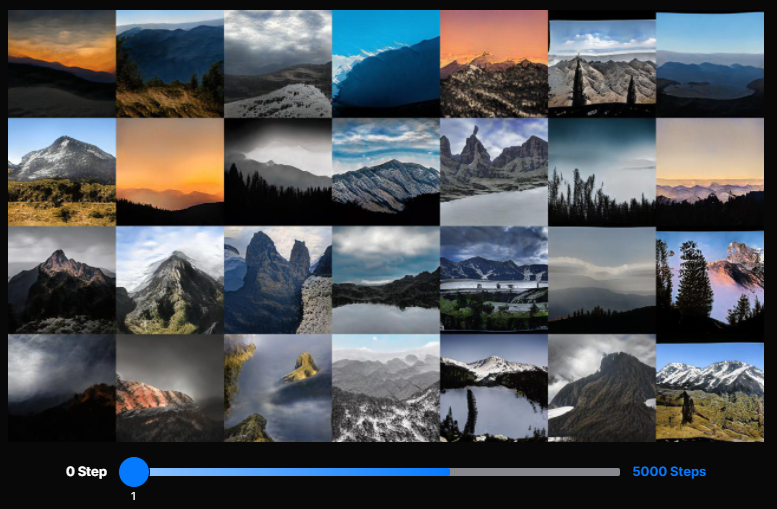
Resulting video from the audio mix and a model weight form styleGAN, my dataset, and birds.
Resulting video from the audio mix and a model weight form styleGAN, my dataset, and landscapes.
In the end I think it came out pretty good, I would like to push this further. I want to better understand the relationship between the parameters and the audio input. There are some parts of the video where the link between the audio and the visual is very apparent however, there are parts that have a very strong link. It seems that rhythm to the audio does play a big part, I want to work with the code and see if there is a way to make it work better with spoken word.
For my final project I chose to think about what clergy, holy people, and the like do in their spare time. WATCH TV! Would our robot overloads do the same thing? I venture to guess the would. But what would it look like? Hopefully the end result of this project will represents what the AI might see in it’s mind eye, kind of parallel to how we process and establish neural connections during our sleep – dreams.
I used a base google colab notebook, VisionaryArtGenerator, altered it and then generated 7000 images from the input. Using those images as a dataset, I used a style GAN to create a .pkl file to input into another google colab notebook called Lucid Sonic Dreams.
VisionaryArtGenerator-https://colab.research.google.com/drive/1Zny3nZwzkGqzVd-PBQaEK48w9HC2SaL_?usp=sharing
Original .pkl to start the process-https://drive.google.com/file/d/1Vsx7oGYhGchjHyOs2UOzofaNNULsc3yJ/view?usp=sharing
https://colab.research.google.com/drive/1T6D9Dkjak19tiynIEBIIk4ozZbJd1yFN?usp=sharing
https://colab.research.google.com/drive/1T6D9Dkjak19tiynIEBIIk4ozZbJd1yFN?usp=sharing